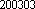This text is meant for people who have never build their own small
processor/controller system yet.
It's really fun and not as difficult as it seems, but it is a lot of
work. Consider doing it together with some friends. Preferably people
with different interests like hardware and software.
How to choose a processor?
First of all consider that for about $300 you can buy the latest state
of the art pentium board complete with processor and memory, so when
you're building a system yourself it's not to build a super computer
but it's just for fun. Therefore I propose you choose a nice 8-bit processor
or controller. Easy of use, simplicity and a nice instruction set will
save you time. I would propose using a 6811, but you can also use a
PIC, AVR or super8/Z8/Z80 for example. The advantage of using a
controller (so a processor with added peripherals) over a processor
is that you get a lot of free (and preconnected!) peripherals for free.
How to design the memory map?
Most microcontrollers already come with some RAM and ((E)E)PROM*.
When this is not the case or you want more memory of these kinds,
you'll have to add extra memory. It's not difficult. These days
32Kbyte (or bigger) SRAM* and EPROM* is easy to get, so I propose
that you split the memory map in one halve of ROM and one of RAM.
Determine first where your processor has it's vectors in memory.
These vectors are used when a reset or interrupt occurs.
The early Motorola processor designs normally have their vectors
at the end of the memory and the Intel-like processors at the start.
Put the ROM there and the RAM in the other halve. This means that
you must connect the /CS (inverted chip select) of the ROM to A15
(or /A15) and the RAM in the opposite way. This will usually cost
one invertor unless the RAM (62256) or the ROM (27256) also has
a non-inverted chip select.
When you can't get these small parts anymore you can also buy
bigger parts and just use part of their memory space. Make
sure however not to leave the upper address lines open. For EPROM*
you can leave them open but then you'll have to put the program
several times in the memory which takes a lot of programming time.
You can also consider making the upper address lines settable
by DIP switches so you can put subsequent test versions of your
program in different parts of the (E)EPROM*.
A lot of hardware designers have a big emotional problem with
wasting the RAM space and provide therefore some bank switching
mechanism, but those are very difficult to use so don't bother...
Connect the address lines from the controller to the address lines
of the RAM and ROM. When possible connect a0 to a0 of each component.
For ROM this is essential when the program is filled in the ROM
by an external source, but for RAM it doesnt't matter when it's
easier to route the lines differently. For debugging purposes
however a one-to-one connection policy is much easier.
The reset circuit is just a switch that connects the /reset line
to 0V to reset the chip. When the switch is not pressed a pull-up
resistor will pull the /reset pin to 5V. The /reset pin also
controls the power-on reset and the requirements for the rise time
on this pin are usually very strict. Use a recommended reset circuit
to save yourself problems. Especially when you want to use your
system ever for a serious purpose.
Connecting a terminal
The easiest way to talk to your system is using a terminal or a terminal
program (like the standard one under Windows) on a PC. Therefore you
have to make an RS-232 connection to your system. This is quite easy to
do using a MAX232 (or equivalent). This part generates it's own +12 and
-12 voltages using powerpumps and a few discrete components like
capacitors. When your power supply has +12V and -12V you can also use
simpler RS-232 drivers and receivers.
You'll also need a 9 or 25 pin subminiature-D card edge (for example) connector.
Or you can put an 8 pin connector on your board which is also used to put jumpers
on. This system was also used on AT-style motherboards and the earlier IO* cards.
You can use a standard PC part to connect from your system board to your casing.
Beware however that your system should not be considered to be a terminal (like
a PC) but a host, so I'd like to put a female connector on it. The fact that the
PC uses male connectors is strange anyway...
Alternative I/O
Instead of connecting a terminal you can also connect some sort of display and
keys on your system, but for debugging purposes I'd add a RS-232 connection anyway,
since especially with the UART that is usually build into the controller it's very
easy to do UART output later when you'll be writing your first test program.
To power your system, you'll need a power supply. I suggest you use an old PCpower
supply. Consider however that switching power supplies like these need a minimum
load and I'm not sure if in all cases the blower is load enough. When in doubt
you can connect a harddisk or an old motherboard as extra load.
I propose that you don't use the normal motherboard power supply connector but
one of those that are intended for connecting the floppy etc.
When using a modern power supply make sure that the soft-power-off option doesn't
require that a motherboard is connected...
Actually making the board
When you want to do this really right you'll have to use a
PCB design program.
Finding a cheap or free one and mastering it and having real PCB's made (or make
them yourself, see here) is too much trouble I'd think,
so do what we often did for prototypes. Try to find 'monkey hair' as we used to
call it. It's very thin copper wire with transparent lacquer on it. It's used
for winding transformers I think. To solder it, you put the end of the wire against
your soldering iron till the lacquer burns away. Then you solder the bare copper
to one end of the line you want to lay. Now you stretch the wire to the other end
of the connection cut it, burn of the lacquer and solder it. You can also connect
through to further points once you get good... A disadvantage of this method
is that once you have a bundle of wires on your board it become quite a mess and
when you ever have to change things again, it's very difficult. It often helps
to lay a kind of busses around small soldered on hooks for example.
For small sub 100 connections the technique works great however.
Testing the board
When your board is ready... Apply the power and measure if the supplied power
is correct. The 5V should be between 4.75 and 5.25 V but will probably be much
closer to 5V. Then test if the address lines are running. Even when there is no
program in the ROM yet, the processor/controller should probably be running
through it's entire memory. This may not always be the case don't be too quick
in drawing conclusions. Some controllers may start up in internal mode and some
processors may read data that may constantly make them jump back to the same
starting point.
When you see however the typical pattern of frequencies on the address lines
with each successive address line being halve the frequency of the previous one,
then you can go on to the next step. (Otherwise the crystal or reset circuit are
usually to blame, this may take a while to resolve...)
How to measure these things?
Having an oscilloscope would be nice, but don't overestimate it's usefulness.
Usually they take a lot of time to learn to use and their usefulness is very limited
for this kind of work compared to their cost.
Alternatives are using a multimeter or just a LED. You can also use crystal earphone
to listen at frequencies. Post order companies like Conrad sell a lot of cheap
devices that can show levels and sometimes even frequencies. One of us had developed
his own gadget like this with a binary counter and a line of LED's that we used
much more than the scope.
When using a LED. Put it on address line a15. It should blink with a frequency of
about 1 Mhz/65536=~15 Hz which should be visible. Perhaps you can replace the crystal
with a slower one temporarily? When using an earphone consider that the human ear can
hear from about 300 Hz to 10000 Hz, so address line a6 or thereabouts should give a
about a 1000 Hz tone.
Perhaps you can also use a simple oscilloscope program on your PC which gets his input
from the parallel printer port... Or you can connect the signal to the microphone
input of your soundcard? Do this at your own peril! (Or have the microphone listen to
that crystal earphone...)
(Well if nothing else you have probably learned by now that debugging is a creative
process and all tricks are allowed... ;-)
And now the software!
Suppose you feel your system seems to work, you'll want to write your first
test program. Keep this program as simple as possible. You can either try to
output a character to the terminal or you can toggle some output (with a LED
attached). I usually tried to output a 'J' (because of my name 'Jaap') to the
terminal.
Here is what your minimal program usually has to do:
Start via the reset vector or from the standard start location (address 0x0000 for example).
Initialize the UART.
Put the character in the data out register of the UART.
Loop forever in an idle loop.
Make sure to write the complete program without using any RAM, just to be on the
safe side. This also means that you are not allowed to use subroutine calls.
Really tough heroes start by writing a complete program including stack pointer
initialization (don't forget!!!) which can immediately play chess or bridge, only
to discover that the program doesn't start up...
When the character doesn't make it to the terminal, first check your program again.
Disassemble it or check the binary code by hand (it's still very small). Make sure that
the UART was initialized properly (at the same baudrate as the terminal etc.). Make also
sure that your terminal program or terminal is working correctly (connect an external
modem for example and get the 'READY' after typing an 'AT' command).
Then check that the RS-232driver is connected correctly to your controller. When you have
the possibility try to see if the character is visible before the signal goes into the
RS-232driver.
When all this doesn't solve the problem, we must assume that the program is not being
executed correctly. Check if you haven't crossed any address lines from the controller
to the ROM. You can also look at the signals on the address lines. When the program is
correctly doing it's final loop, all address lines should be constantly the same value
except for address a0 and perhaps a1.
Well this is the second phase in the debugging process that may take some time, but it's
nice puzzle. When everything else fails post your problem on an appropriate mailing list
or in newsgroup. A lot of people like helping with this kind of problem because it
brings back memories...
When IT DOES WORK as planned.
Now you can really start programming. First you still need to test if your RAM
works, but I'd take a bigger step here (unless you're using DRAM). One of the first
things to do is write UART drivers. You'll need a routine to send a character and to
get a character. Really sophisticated UART routines are based on interrupts, but that
is often not really necessary (and quite complex). Just write an output routine that
waits until the previous character has been sent (or actually has been promoted to the
output register) and then puts the new character in the output register.
Also write a routine that checks if a new character has been received and a routine
that gets the latest character and a routine that waits until a character has been
received and then returns it. When you want to have simple ctrl-c interupting behaviour
you'll need to have the output routine check if there is input and if so check if it's
a ctrl-c or another interrupting character. If so the output routine will have to
interrupt the running foreground program and return to a known state. Otherwise the
preread character will have to be saved for the input routines. From now on the input
routines, first will have to check if there was already a character buffered by the
output routine. Still quite simple. By the way, we are assuming that your system
will either constantly produce output or will be waiting for input, so the input is
constantly monitored for interrupting characters. When your system will be calculating
things for a long period (which is unlikely) you'll need a more sophisticated UART driver.
We are also assuming that your terminal is fast enough to accept all output as it comes
and that it canbuffer all output of your system when the user has pressed 'Scroll Lock'.
Otherwise you'll have to add an Xon-Xoff handshaking mechanism (which is still quite
easy to implement in the given situation).
Well, by now we're talking about driver writing instead of building your own system.
Perhaps more on these things later... (Let me know when you'd appreciate it.)
A sample project using the 8085
Lewis Stockill gave me the data of a completed
8085 hobby project (that I helped him
with) to put in the Chipdir as an example project.
Here are the schematics for a similar Z80 project:
ftp.psyber.com/dibsed/CIRCATS/ - See the 00index.txt and z80*.* files